java并发编程
java并发编程
Note: 文中的示例代码,基于JDK11
并发主要是解决三个核心问题的
- 原子性 典型的就是java代码中的i++,看着是一行代码,但是编译完了实际CPU执行的不是一条指令
- 可见行 一个线程对共享变量的修改,另外一个线程能立刻看到。实际中因为CPU缓存的问题,并不能立即看到。
- 有序性 程序执行的顺序不是按照代码的顺序来执行的,实际中编译器优化代码会改变程序中语句的先后顺序指令的重排序,或者是CPU执行的乱序问题。
线程
先看代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
public class HelloWorld {
public static void main(String[] args) {
System.out.println(“Hello World......”);
new Thread() {
public void run() {
System.out.println(“另外一个线程干的事儿......”);
}
}.start();
// 还有一些其他的代码
}
}
执行main方法相当于其实是启动一个jvm进程 jvm进程里,是有很多线程的,你能看到第一个的线程就是main线程
main线程就是负责执行你的main方法里的那些代码,比如说执行System.out.println这行代码,打印一些东西出来,
只要你的线程执行完了这段代码之后,其实jvm进程他也就退出了
启动一个java的系统,通过执行一个main方法,java -jar这样的命令来启动,jvm进程,里面是有线程的,main线程,负责执行main方法里的代码
如果main线程执行完了以后,jvm进程默认就会直接退出
什么是多线程并发编程?
一个jvm进程里,你除了main线程,你还可以在main线程里开启别的线程,别的线程是跟main线程同时在运行的。
没有先后顺序,多线程并发运行的时候,本质是CPU在执行各个线程的代码,一个CPU会有一个时间片算法,他一会儿执行main线程,一会儿执行Thread线程,看起来两个线程好像是在同时运行一样
只不过CPU执行每个线程的时间特别短,可能执行一次就几毫秒,几微妙,你是感觉不出来的,看起来好像是多个线程并发在运行一样
什么是并发编程?
用多线程来编程,实现复杂的系统功能,让多个线程同时运行,干各种事情,最终完成一套复杂系统需要干的所有的事儿
- 控制多线程实现系统功能
- Java内存模型以及volatile关键字
- 线程同步以及通信
- 锁优化
- 并发编程设计模式:基于多线程实现复杂系统架构
- 并发包以及线程池
线程在JVM中的几种状态? java.lang.Thread.State中定义了线程的集中状态
- NEW Thread state for a thread which has not yet started. 没有调用start()方法
- RUNNABLE A thread executing in the Java virtual machine is in this state. 调用start()
- BLOCKED A thread that is blocked waiting for a monitor lock is in this state.
- WAITING A thread that is waiting indefinitely for another thread to perform a particular action is in this state.
- TIMED_WAITING A thread that is waiting for another thread to perform an action for up to a specified waiting time is in this state.
- TERMINATED A thread that has exited is in this state.
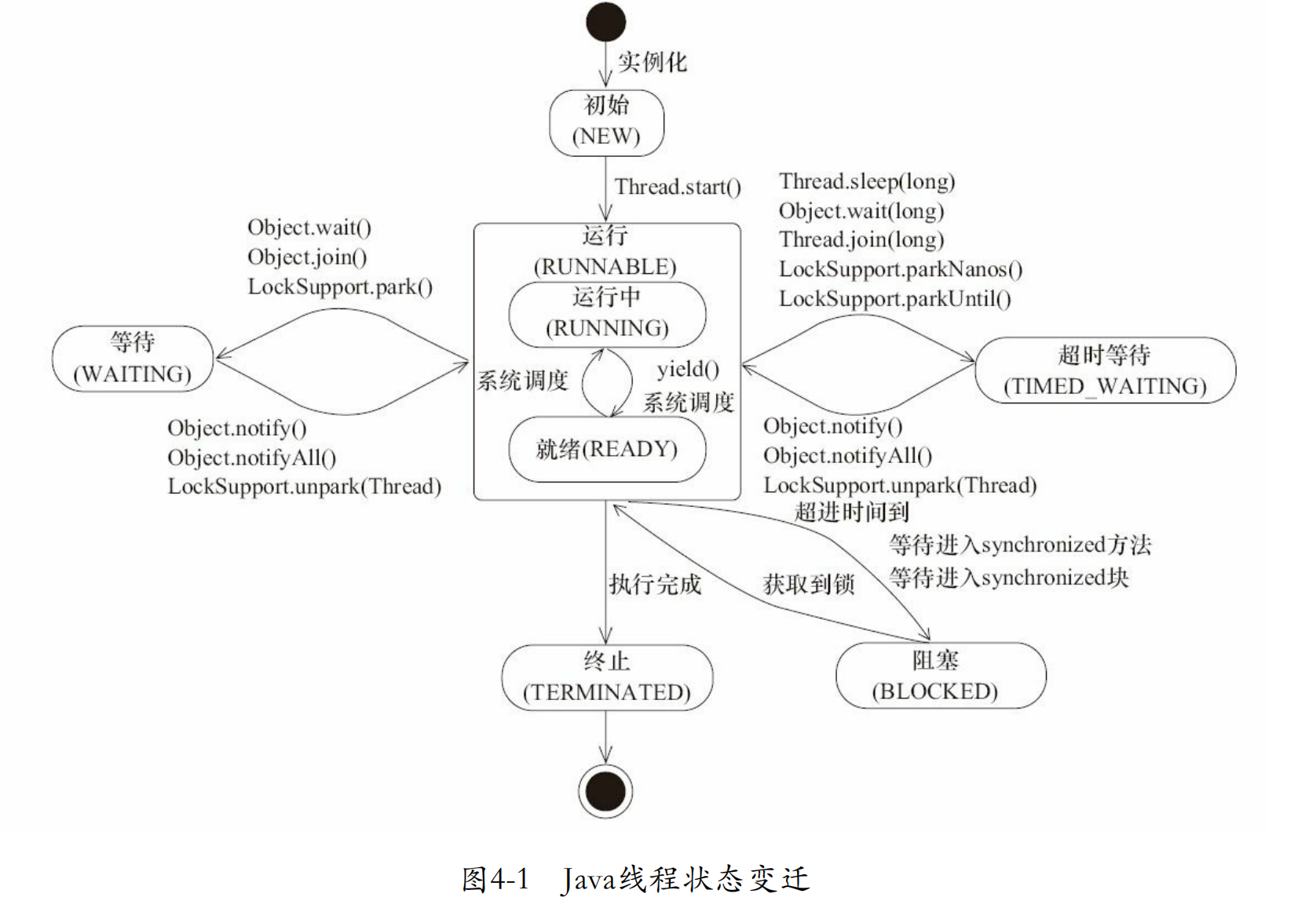
线程组/ThreadGroup
线程组,其实意思就是你可以把一堆线程加入一个线程组里,那关键这个玩意儿有啥好处?好处就是,你可以将一堆线程作为一个整体,统一的管理和设置
实际上在java里,每个线程都有一个父线程的概念,就是在哪个线程里创建这个线程,那么他的父线程就是谁。举例来说,java都是通过main启动的,那么有一个主要的线程就是mian线程。在main线程里启动的线程,父线程就是main线程,就这么简单。
然后每个线程都必然属于一个线程组,默认情况下,你要是创建一个线程没指定线程组,那么就会属于父线程的线程组了,main线程的线程组就是main ThreadGroup。咱们来随手写一段代码看看不就得了
在java里面,线程都是有名字的,默认情况下,main线程的名字就是叫main。你其他的其他线程的名字,一般是叫做Thread-0之类的。ServiceAliveMonitor线程的父线程是main线程,默认的线程组也是main线程的线程组,叫做main
然后我们也可以手动创建一个线程组,将线程加入这个线程组中
但是线程组其实也有父线程组的概念,我们创建线程组的时候,如果没有手动指定他的父线程组,那么其实默认的父线程组就是main线程的线程组
默认线程会加入父线程的ThreadGroup,或者你自己手动创建ThreadGroup,ThreadGroup也有父ThreadGroup,ThreadGroup可以包裹一大堆的线程,然后统一做一些操作,比如统一复制、停止、销毁,等等
1
2
3
4
5
enumerate():复制线程组里的线程
activeCount():获取线程组里活跃的线程
getName()、getParent()、list(),等等
interrupt():打断所有的线程
destroy():一次性destroy所有的线程
当你真的需要用到他的时候,去查阅jDK的API文档,我觉得是最好的办法
JDK虽然提供了ThreadGroup,但是一般平时自己开发,或者是很多的开源项目里,ThreadGrdoup很少用,其实如果你要自己封装一堆线程的管理组件,我觉得你完全可以自己写
线程优先级
设置线程优先级,理论上可以让优先级高的线程先尽量多执行,但是其实一般实践中很少弄这个东西,因为这是理论上的,可能你设置了优先级,人家cpu结果也还是没按照这个优先级来执行线程.
这个优先级一般是在1~10之间 而且ThreadGroup也可以指定优先级,线程优先级不能大于ThreadGroup的优先级 但是一般就是用默认的优先级就ok了,默认他会用父线程的优先级,就是5
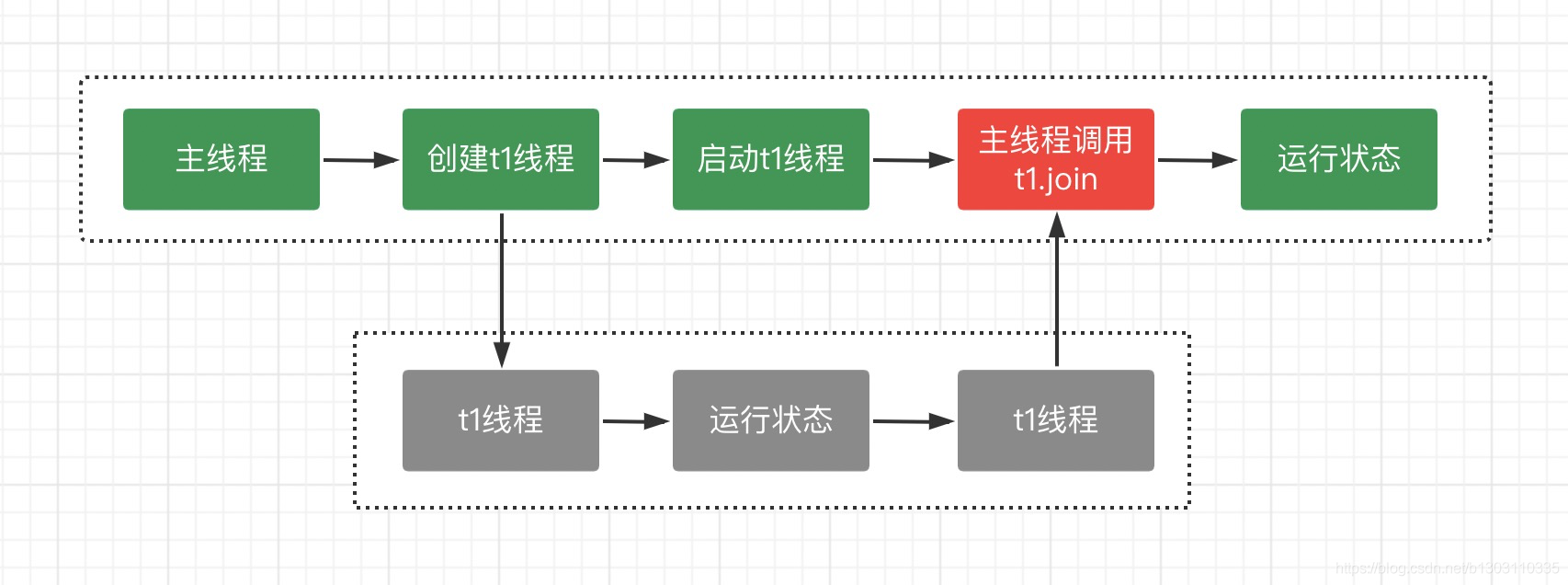
Thread.join()
CPU多级缓存
CPU为了加快处理数据的速度,加入了缓存,加缓存的原则,依赖于局部性原理:
- 时间局部性 某个数据项被访问后,可能很快会被再次访问的特性。
- 空间局部性 某个数据项被访问后,与其地址相近的数据项可能很快被访问的特性。
我们可以利用局部性原理将计算机的存储器组织成为存储器层次结构。
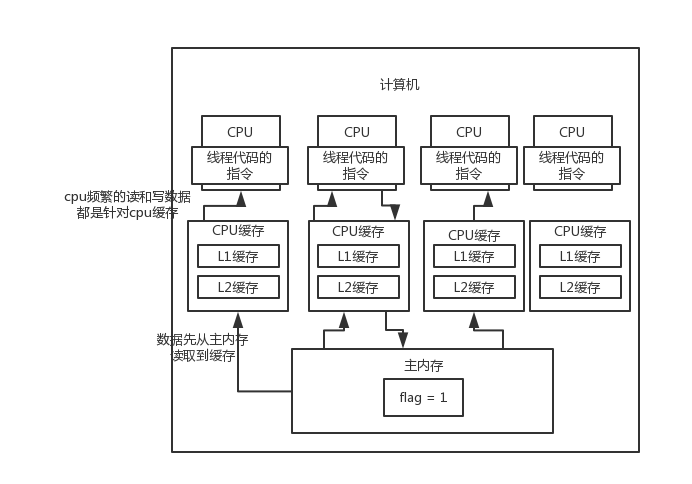
缓存的最小单位是缓存行(cache line),现在主流的CPU缓存行是 64bytes Linux 系统可以通过cat /sys/devices/system/cpu/cpu0/cache/index0/coherency_line_size命令查看缓存行大小。
Mac 系统可以通过sysctl hw.cachelinesize查看缓存行的大小。
缓存一致性问题 Cache coherence
cpu缓存模型,其实默认情况下是有问题的,特别是多线程并发运行的时候,导致说各个cpu的本地缓存,跟主内存,没有同步,一个数据,在各个地方,可能都不一样,就会导致数据的不一致 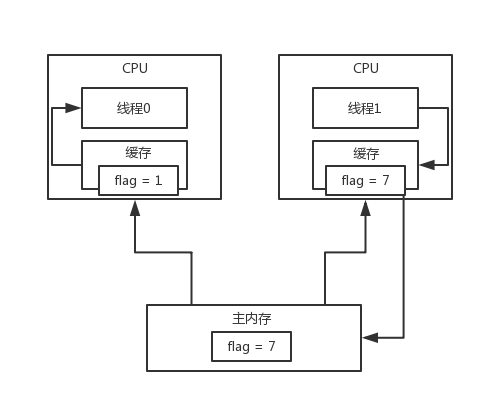
缓存一致性协议
存储系统的一致性定义:
- 处理器P对位置X的写操作后面紧跟着处理器P对X的读操作,并且在这次读操作和写操作之间没有其他处理器对X进行写操作,这时读操作总是返回P写入的数值
- 在其他处理器对X的写操作后,处理器P对X执行读操作,这两个操作之间有足够的间隔并且没有其他处理器对X进行写操作,这时,读操作返回的是写入的数值。
- 对同一个地址的写操作是串行执行的, write serialization
cache提供数据的迁移和复制: 迁移: 数据项可以移入本地cache并以透明的方式使用。 复制: 当共享数据被同时读取时,cache在本地对数据项做了备份。 上述两种操作的支持,对于可以提高访问共享数据的性能。
为解决缓存一致性问题,提出了很多协议,统称为缓存一致性协议,最常用的一类是监听协议(snooping protocol),还有一类是Directory-based。 监听协议又分为write-invalidate protocols 和 write-update protocols 协议
假共享false sharing 当两个不相关的共享变量放在相同的cache块中时,尽管每个处理器访问的事不同的变量,但是在处理器之间还是将整个块进行交换
一些常用的协议:
MESI协议:MESI是最早被采用的一种缓存一致性协议。它将每个缓存块的状态分为四种:Modified、Exclusive、Shared和Invalid,通过控制每个缓存块的状态来保证缓存一致性。
MSI协议:MSI协议将每个缓存块的状态分为三种:Modified、Shared和Invalid。与MESI协议相比,它没有Exclusive状态,但增加了一个Shared状态。MSI协议的缺点是在共享状态下会存在大量的无效传输。
MOSI协议:MOSI协议是对MSI协议的改进,增加了一个Owner状态,用于避免多个核心同时竞争缓存块的问题。
MESIF协议:MESIF协议是对MESI协议的改进,增加了Forward状态,用于提高缓存的利用率和传输效率。
MOESI协议:MOESI协议是对MESI协议的改进,增加了Owner状态,用于避免多个核心同时竞争缓存块的问题。同时,MOESI协议还可以在共享状态下直接发送缓存数据,而不是先将其写回主存储器。
IntelCPU使用的是MESIF协议,AMD的CPU使用的是MOESI协议 市面上典型的CPU所用的协议都是通过MESI演变而来的,所以主要理解一下MESI协议
缓存一致性协议 MESI
https://en.wikipedia.org/wiki/MESI_protocol
MESI 是指4中状态的首字母。每个Cache line有4个状态,可用2个bit表示,它们分别是: |状态|描述|监听任务| |–|–|–| |修改 (Modified)|该Cache line有效,数据被修改了,和内存中的数据不一致,数据只存在于本Cache中。|缓存行必须时刻监听所有试图读该缓存行相对就主存的操作,这种操作必须在缓存将该缓存行写回主存并将状态变成S(共享)状态之前被延迟执行。| |独占 Exclusive|该Cache line有效,数据和内存中的数据一致,数据只存在于本Cache中。|缓存行也必须监听其它缓存读主存中该缓存行的操作,一旦有这种操作,该缓存行需要变成S(共享)状态。| |共享 Shared|该Cache line有效,数据和内存中的数据一致,数据存在于很多Cache中。|缓存行也必须监听其它缓存使该缓存行无效或者独享该缓存行的请求,并将该缓存行变成无效(Invalid)。| |无效 Invalid|该Cache line无效。|无|
| M | E | S | I | |
|---|---|---|---|---|
| M | × | × | × | √ |
| E | × | × | × | √ |
| S | × | × | √ | √ |
| I | √ | √ | √ | √ |
Operation: Following are the different type of Processor requests and Bus side requests:
Processor Requests to Cache include the following operations:
PrRd: The processor requests to read a Cache block. PrWr: The processor requests to write a Cache block Bus side requests are the following:
BusRd: Snooped request that indicates there is a read request to a Cache block requested by another processor BusRdX: Snooped request that indicates there is a write request to a Cache block requested by another processor that doesn’t already have the block. BusUpgr: Snooped request that indicates that there is a write request to a Cache block requested by another processor that already has that cache block residing in its own cache. Flush: Snooped request that indicates that an entire cache block is written back to the main memory by another processor. FlushOpt: Snooped request that indicates that an entire cache block is posted on the bus in order to supply it to another processor (Cache to Cache transfers).
State Transitions and response to various Processor Operations |Initial State|Operation|Response| |–|–|–| |Invalid(I)|PrRd|Issue BusRd to the bus
other Caches see BusRd and check if they have a valid copy, inform sending cache
State transition to (S)Shared, if other Caches have valid copy.
State transition to (E)Exclusive, if none (must ensure all others have reported).
If other Caches have copy, one of them sends value, else fetch from Main Memory| ||PrWr|Issue BusRdX signal on the bus
State transition to (M)Modified in the requestor Cache.
If other Caches have copy, they send value, otherwise fetch from Main Memory
If other Caches have copy, they see BusRdX signal and invalidate their copies.
Write into Cache block modifies the value.| |Exclusive(E)|PrRd|No bus transactions generated
State remains the same.
Read to the block is a Cache Hit| ||PrWr|No bus transaction generated
State transition from Exclusive to (M)Modified
Write to the block is a Cache Hit| |Shared(S)|PrRd|No bus transactions generated
State remains the same.
Read to the block is a Cache Hit.| ||PrWr|Issues BusUpgr signal on the bus.
State transition to (M)Modified.
other Caches see BusUpgr and mark their copies of the block as (I)Invalid.| |Modified(M)|PrRd|No bus transactions generated
State remains the same.
Read to the block is a Cache hit| ||PrWr|No bus transactions generated
State remains the same.
Write to the block is a Cache hit.|
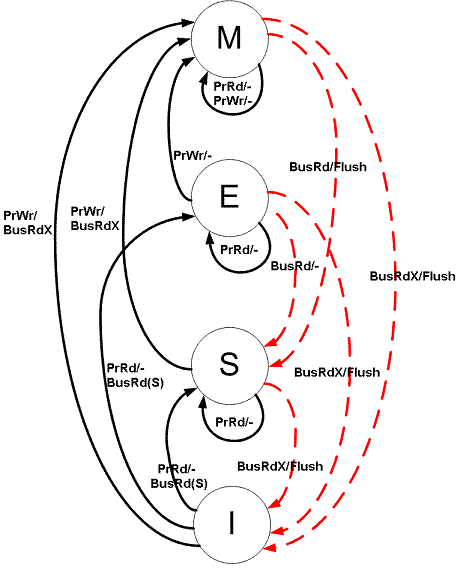 State diagram for MES protocol Red: Bus initiated transaction. Black: Processor initiated transactions
State diagram for MES protocol Red: Bus initiated transaction. Black: Processor initiated transactions
为了进一步的压榨CPU,提出了两个组件来减少因MESI协议带来的CPU等待时间
- Store Buffer CPU 在写操作时,可以不等待其他 CPU 响应消息就直接写到 store buffer,后续收到响应消息之后,再把 store buffer 里面的数据写入缓存行。 CPU 读数据的时候,也会先判断一下 store buffer 里面有没有数据,如果存在,就优先使用 store buffer 里面的数据(这个机制,叫做“store forwarding”)。 从而提高了 CPU 的利用率,也能保证了在同一CPU,读写都能顺序执行。
- Invalidate Queue 主要作用就是提高 invalidate 消息的响应速度。
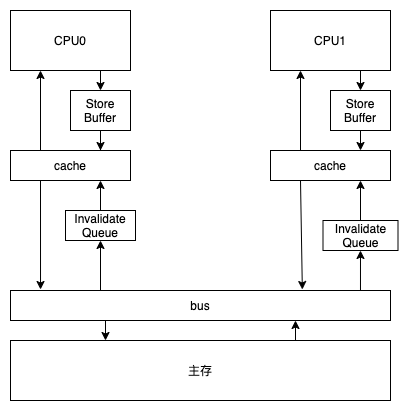
两个组件相应的带来了一些问题,因为缓存不能及时的同步到其他的CPU缓存,会导致一定的指令重排序问题。然后CPU就把这个问题抛给了开发人员来自行解决,也就是所谓的内存屏障。大部分问题可以只处理其中的一个就行,然后又把内存屏障分成了: 写屏障 Store Memory Barrier will flush the store buffer, ensuring all writes have been applied to that CPU’s cache 读屏障Load Memory Barrier A read barrier will flush the invalidation queue, thus ensuring that all writes by other CPUs become visible to the flushing CPU.
https://heapdump.cn/article/3971578
一个可以模拟MESI协议的动画交互网站 https://www.scss.tcd.ie/Jeremy.Jones/VivioJS/caches/MESIHelp.htm
JMM java memory model
起源于JSR-133 Java Language and Virtual Machine Specifications
由于各种jvm虚拟机,os,CPU的实现机制不同,还是从java角度理解到JMM这一层就OK我觉得。
Volatile
java中可以把字段声明为volatile的。比如:
1
2
3
4
public class AtomicInteger extends Number implements java.io.Serializable {
// volatile变量
private volatile int value;
}
但是volatile启什么作用呢?
变量声明为volatile之后,通过JMM来保证所有线程看到的字段值是一致的。 还有就是限制指令重排序,volatile之前的命令不会排到后面去,后面的代码不会排到前面去
怎么做到这一点的呢? 先对比一下变量添加volatile的前后变动 添加前
int v;
descriptor: I
flags:
添加后
volatile int v;
descriptor: I
flags:ACC_VOLATILE
class文件中变量flags: ACC_VOLATILE
以自己的AMDcpu分析: 通过分析java实际过程中的汇编代码,我们发现,加了volatile的变量,在保存的时候 多了一行汇编指令lock addl $0x0,(%rsp)
查询 IA32 手册: 在执行相应指令时,使处理器的LOCK#信号被激活(将指令转换为原子指令)。在多处理器环境中,LOCK#信号确保在信号被激活期间,处理器独占任何共享内存。
Bus locking, using the LOCK# signal and the LOCK instruction prefix.
For the P6 and more recent processor families, if the area of memory being locked during a LOCK operation is cached in the processor that is performing the LOCK operation as write-back memory and is completely contained in a cache line, the processor may not assert the LOCK# signal on the bus. Instead, it will modify the memory location internally and allow it’s cache coherency mechanism to ensure that the operation is carried out atomically. This operation is called “cache locking.” The cache coherency mechanism automatically prevents two or more processors that have cached the same area of memory from simultaneously modifying data in that area.
LOCK# 前缀指令会触发StoreBuffer写入主存的逻辑, 限制使用的命令ADD, ADC, AND, BTC, BTR, BTS, CMPXCHG, CMPXCH8B, CMPXCHG16B, DEC, INC, NEG, NOT, OR, SBB, SUB, XOR, XADD, XCHG.
总结下来就是lock前缀指令 + 缓存一致协议来实现的
写的比较好的lock前缀指令解析: https://blog.csdn.net/reliveIT/article/details/90038750
double check的问题
https://en.wikipedia.org/wiki/Double-checked_locking#
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
// Broken multithreaded version
// "Double-Checked Locking" idiom
class Foo {
private Helper helper;
public Helper getHelper() {
if (helper == null) {
synchronized (this) {
if (helper == null) {
// 这一行会出问题是因为,这一块实际CPU执行不是原子性的,jvm会先分配一块内存给对象,然
// 后再执行初始化,这样的话,会导致后面来的线程误以为helper已经初始化了,就不走lock代码,直接return
// 后面如果立即执行helper中的方法,此时因为helper还没初始化完毕,所以会出现问题
helper = new Helper();
}
}
}
return helper;
}
// other functions and members...
}
解决上面的问题就是加volatile关键字
JMM中的happens-before 有一条限定 A write to a volatile field happens-before every subsequent read of that field.
也就是说,其他线程必须要等到,helper字段写完之后才能去读,至此才解决了此问题
// TODO 深入理解CPU
Syncroynized
Java语法中加入syncroynized关键字后
1
2
3
synchronized(class) {
...
}
对应的class文件中会出现 monitorenter,monitorexit
1
2
3
10: monitorenter
...
28: monitorexit
底层原理 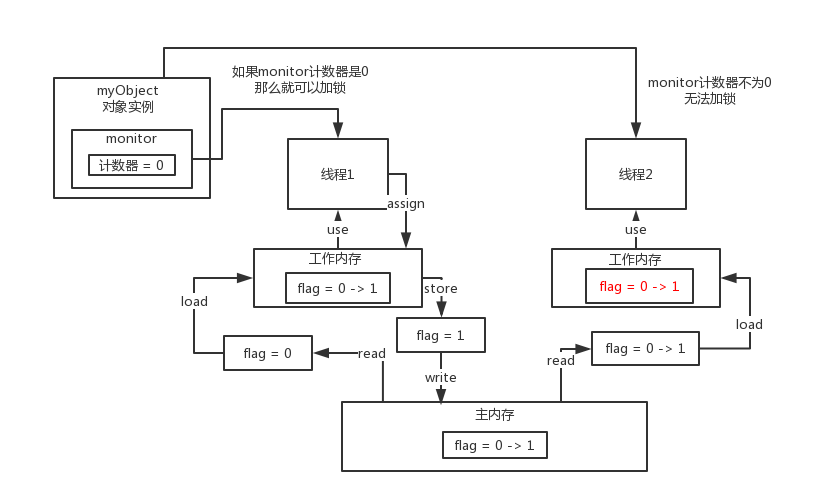
每个对象都有一个关联的monitor,比如一个对象实例就有一个monitor,一个类的Class对象也有一个monitor,如果要对这个对象加锁,那么必须获取这个对象关联的monitor的lock锁 monitor里面有一个计数器,从0开始的。如果一个线程要获取monitor的锁,就看看他的计数器是不是0,如果是0的话,那么说明没人获取锁,他就可以获取锁了,然后对计数器加1
monitor的锁是支持重入加锁的
1
2
3
4
5
6
synchronized(myObject) {
// 一大堆的代码
synchronized(myObject) {
// 一大堆的代码
}
}
如果一个线程第一次synchronized那里,获取到了myObject对象的monitor的锁,计数器加1,然后第二次synchronized那里,会再次获取myObject对象的monitor的锁,这个就是重入加锁了,然后计数器会再次加1,变成2
这个时候,其他的线程在第一次synchronized那里,会发现说myObject对象的monitor锁的计数器是大于0的,意味着被别人加锁了,然后此时线程就会进入block阻塞状态,什么都干不了,就是等着获取锁
接着如果出了synchronized修饰的代码片段的范围,就会有一个monitorexit的指令,在底层。此时获取锁的线程就会对那个对象的monitor的计数器减1,如果有多次重入加锁就会对应多次减1,直到最后,计数器是0
然后后面block住阻塞的线程,会再次尝试获取锁,但是只有一个线程可以获取到锁
synchronized能保证可见性和原子性、有序性
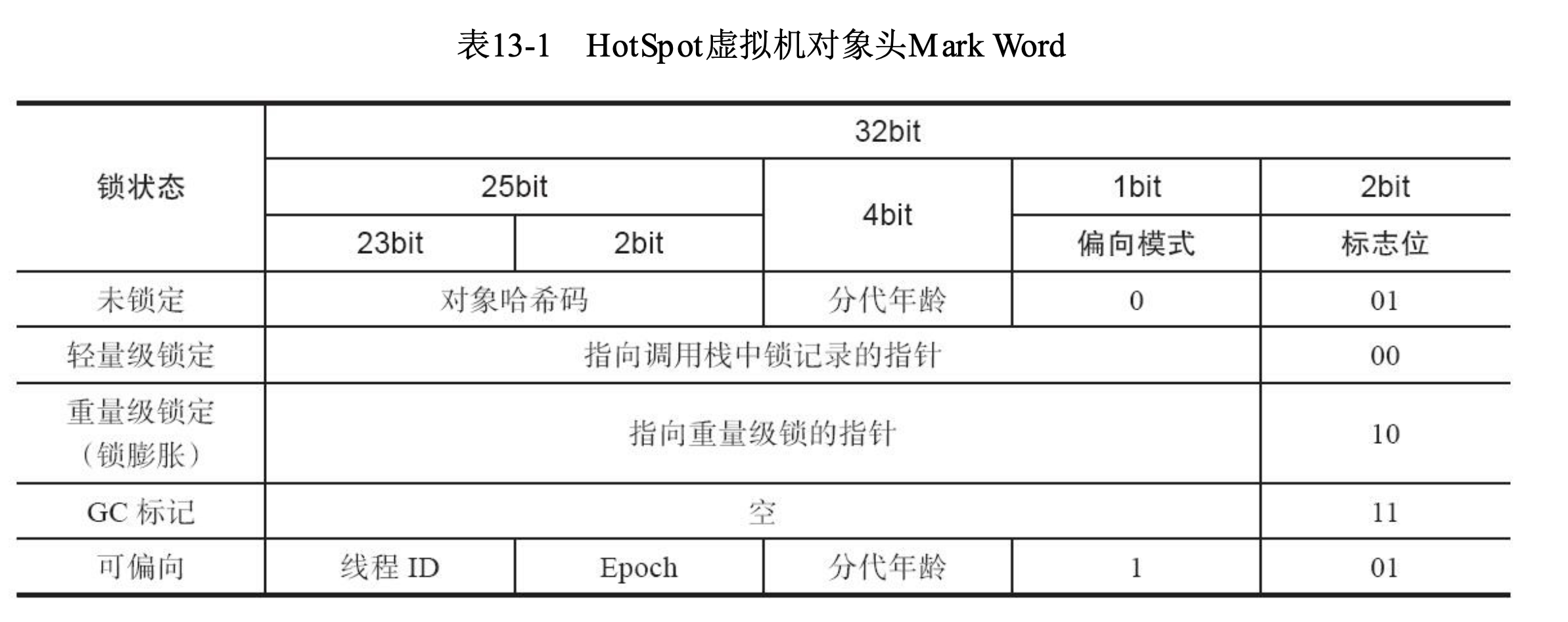 对象头的具体数据结构在源码中的
对象头的具体数据结构在源码中的markWord.hpp文件中
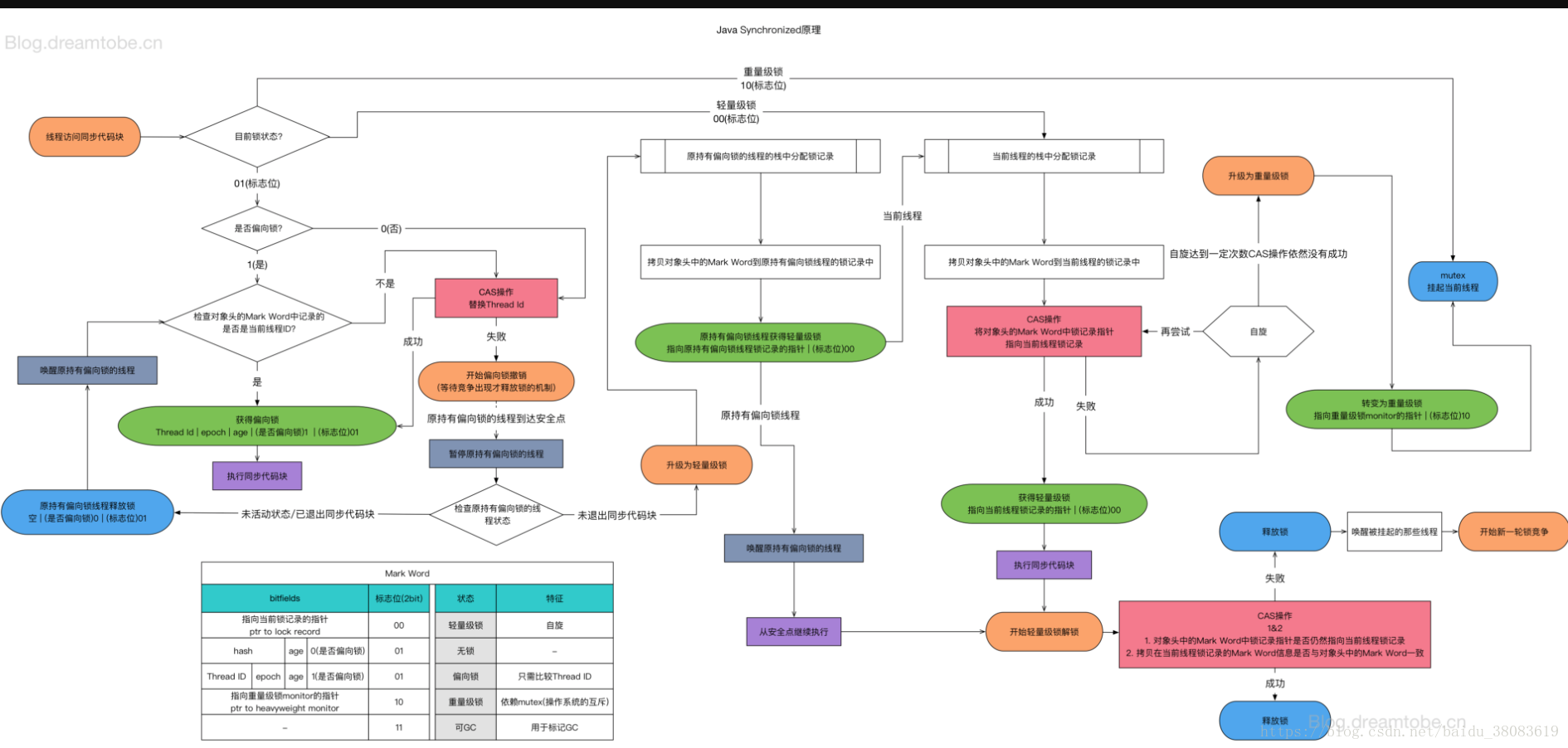
JDK1.6之后,JVM对synchronized做了一系列优化,这些技术都是为了在线程之间更高效地共享数据及解决竞争问题,从而提高程序的执行效率。其中包括
- 自适应自旋(Adaptive Spinning)
自旋锁的定义: 为了让线程等待,我们只须让线程执行一个忙循环(自旋),这项技术就是所谓的自旋锁。 自旋锁在JDK 1.4.2中就已经引入,只不过默认是关闭的,可以使用-XX:+UseSpinning参数来开 启,在JDK 6中就已经改为默认开启了。 自旋的默认次数是10次,可以通过-XX:PreBlockSpin 来修改
JDK1.6引入的自适应自旋,指自旋的时间不是固定的,而是有前一次在同一个锁上的自旋时间及锁的拥有者的状态来决定的。
- 锁消除(Lock Elimination)
锁消除,指JVM的即时编译器在运行时,对一些同步的代码块,进行分析,如果检测到不存在共享数据竞争的时候,就把锁消除掉。 具体的分析技术,使用的是逃逸分析技术。
- 锁膨胀/锁粗化(Lock Coarsening)
原则上,我们编写代码的时候,是尽量要缩小锁的范围的,这个是没有问题的。但是,如果有一系列操作反复的加锁、释放锁, 比如在循环体内部,JIT时,需要把锁的粒度提到循环体的外部,减少锁竞争带来的性能损耗。
- 轻量级锁(LightWeight Locking)
JDK6,新加入的锁类型,其中轻量级是相对使用操作系统的互斥量实现的传统锁而言的。
轻量级锁的大概原理就是第一次加锁的时候会通过CAS的方式,如果成功的话就标记为轻量级的锁机制,如果失败的话则说明有其它线程在竞争锁,则退化为重量级锁
做这个事主要是依据的是”对于绝大部份的锁,在整个同步周期内都是不存在竞争的“这一经验法则。
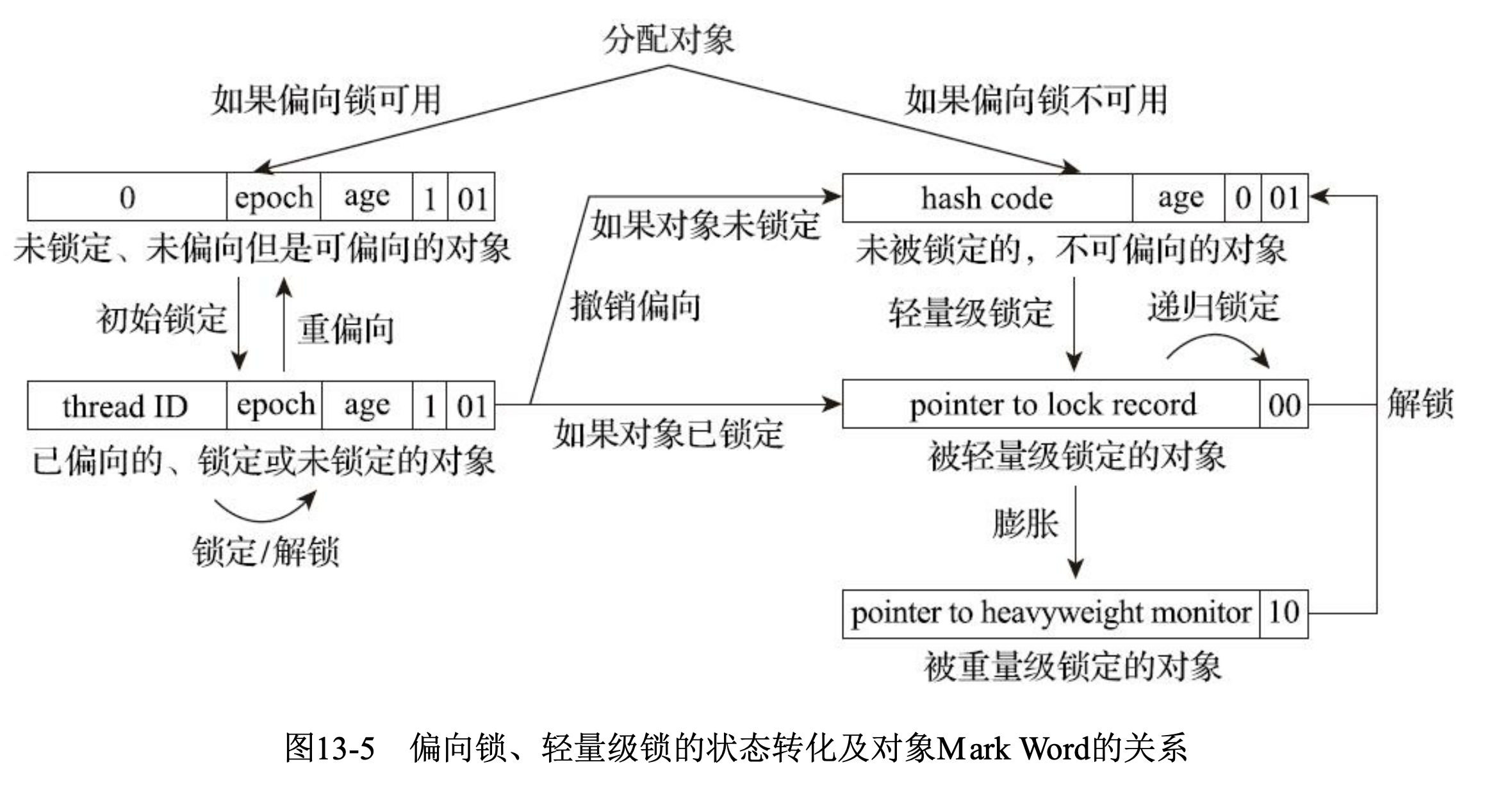
| 锁状态 | 偏向标志 | 锁标志位 | Mark Word 内容特征 | 备注 |
|---|---|---|---|---|
| 未锁定 (Unlocked) | 0 | 01 | HashCode (31b) + 年龄 (4b) | 对象的初始状态 |
| 偏向锁 (Biased) | 1 | 01 | ThreadID + Epoch + 年龄 | 锁偏向特定线程,无竞争 |
| 轻量级锁 (Stack-locked) | (无) | 00 | 指向栈中锁记录的指针 | 线程通过 CAS 在栈帧创建记录 |
| 膨胀中 (Inflating) | (无) | 00 | 全 0 (0x00000000...) | 过渡状态,正在创建 Monitor |
| 重量级锁 (Inflated) | (无) | 10 | 指向 ObjectMonitor 的指针 | 包含等待队列,由 OS 互斥量实现 |
| GC 标记 (Marked) | (无) | 11 | (通常为 0 或记录转发指针) | CMS 或 GCLive 标记时使用 |
- 偏向锁(Biased Locking)
JDK6中引入的一项锁优化措施。目的是消除数据在没有竞争的情况下的同步原语,进一步提高程序性能。 如果说轻量级锁是在无竞争情况下使用CAS操作去消除同步使用的互斥量,那偏向锁就是在无竞争的情况下把整个同步都消除掉,连CAS都不做了。
由于偏向锁的对象头会占用hashcode的位置,所以这两个出现了冲突,所以会有以下规则:
- 当一个对象已经计算过hash值后,就再也不能进入偏向锁模式
- 当一个对象正处于偏向锁模式,有收到需要计算hash值的请求,则会主动退出偏向锁模式,并膨胀为重量级锁
锁升级流程 https://www.cnblogs.com/dennyzhangdd/p/6734638.html 这个直接分析的源码贼牛逼
偏向锁的获取ObjectSynchronizer::fast_enter 在HotSpot中,偏向锁的入口位于openjdk\hotspot\src\share\vm\runtime\synchronizer.cpp文件的ObjectSynchronizer::fast_enter函数: 偏向锁的获取由BiasedLocking::revoke_and_rebias方法实现,由于实现比较长,就不贴代码了,实现逻辑如下:
- 通过
markOop mark = obj->mark()获取对象的markOop数据mark,即对象头的Mark Word; - 判断mark是否为可偏向状态,即mark的偏向锁标志位为 1,锁标志位为 01;
- 判断mark中JavaThread的状态:如果为空,则进入步骤(4);如果指向当前线程,则执行同步代码块;如果指向其它线程,进入步骤(5);
- 通过CAS原子指令设置mark中JavaThread为当前线程ID,如果执行CAS成功,则执行同步代码块,否则进入步骤(5);
- 如果执行CAS失败,表示当前存在多个线程竞争锁,当达到全局安全点(safepoint),获得偏向锁的线程被挂起,撤销偏向锁,并升级为轻量级,升级完成后被阻塞在安全点的线程继续执行同步代码块;
偏向锁的撤销 只有当其它线程尝试竞争偏向锁时,持有偏向锁的线程才会释放锁,偏向锁的撤销由BiasedLocking::revoke_at_safepoint方法实现:
- 偏向锁的撤销动作必须等待全局安全点;
- 暂停拥有偏向锁的线程,判断锁对象是否处于被锁定状态;
- 撤销偏向锁,恢复到无锁(标志位为 01)或轻量级锁(标志位为 00)的状态;
偏向锁在Java 1.6之后是默认启用的,但在应用程序启动几秒钟之后才激活,可以使用-XX:BiasedLockingStartupDelay=0参数关闭延迟,如果确定应用程序中所有锁通常情况下处于竞争状态,可以通过XX:-UseBiasedLocking=false参数关闭偏向锁。
当关闭偏向锁功能,或多个线程竞争偏向锁导致偏向锁升级为轻量级锁,会尝试获取轻量级锁,其入口位于ObjectSynchronizer::slow_enter
- 重量级锁
当锁升级为重量级锁时,Mark Word 的低 2 位会变成 10。此时,Mark Word 的其余部分会存储一个指向 ObjectMonitor 对象的指针。
当线程 A 尝试进入 synchronized 块但发现锁已是重量级且被线程 B 持有时:
- 自旋优化:线程 A 不会立刻挂起,而是先进行几次“自适应自旋”。如果这时候线程 B 刚好释放了,那就直接拿锁,省去了内核切换。
- 入队:自旋失败后,线程 A 会被封装成一个 ObjectWaiter 对象,放入 _cxq 队列。
- 阻塞(Park):通过操作系统的系统调用(如 Linux 的 pthread_mutex_lock 或 futex)将自己挂起。
- 唤醒(Unpark):当线程 B 释放锁时,会根据策略从 _EntryList 或 _cxq 中挑选一个线程唤醒。
ObjectMonitor 的内部结构: 在 src/hotspot/share/runtime/objectMonitor.hpp 中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
class ObjectMonitor : public CHeapObj<mtObjectMonitor> {
static OopStorage* _oop_storage;
// The sync code expects the header field to be at offset zero (0).
// Enforced by the assert() in header_addr().
volatile markWord _header; // displaced object header word - mark
WeakHandle _object; // backward object pointer
// Separate _header and _owner on different cache lines since both can
// have busy multi-threaded access. _header and _object are set at initial
// inflation. The _object does not change, so it is a good choice to share
// its cache line with _header.
DEFINE_PAD_MINUS_SIZE(0, OM_CACHE_LINE_SIZE, sizeof(volatile markWord) +
sizeof(WeakHandle));
// Used by async deflation as a marker in the _owner field:
#define DEFLATER_MARKER reinterpret_cast<void*>(-1)
void* volatile _owner; // pointer to owning thread OR BasicLock
volatile jlong _previous_owner_tid; // thread id of the previous owner of the monitor
// Separate _owner and _next_om on different cache lines since
// both can have busy multi-threaded access. _previous_owner_tid is only
// changed by ObjectMonitor::exit() so it is a good choice to share the
// cache line with _owner.
DEFINE_PAD_MINUS_SIZE(1, OM_CACHE_LINE_SIZE, sizeof(void* volatile) +
sizeof(volatile jlong));
ObjectMonitor* _next_om; // Next ObjectMonitor* linkage
volatile intx _recursions; // recursion count, 0 for first entry
ObjectWaiter* volatile _EntryList; // Threads blocked on entry or reentry.
// The list is actually composed of WaitNodes,
// acting as proxies for Threads.
ObjectWaiter* volatile _cxq; // LL of recently-arrived threads blocked on entry.
JavaThread* volatile _succ; // Heir presumptive thread - used for futile wakeup throttling
JavaThread* volatile _Responsible;
volatile int _Spinner; // for exit->spinner handoff optimization
volatile int _SpinDuration;
jint _contentions; // Number of active contentions in enter(). It is used by is_busy()
// along with other fields to determine if an ObjectMonitor can be
// deflated. It is also used by the async deflation protocol. See
// ObjectMonitor::deflate_monitor().
protected:
ObjectWaiter* volatile _WaitSet; // LL of threads wait()ing on the monitor
volatile jint _waiters; // number of waiting threads
private:
volatile int _WaitSetLock; // protects Wait Queue - simple spinlock
}
class ObjectWaiter : public StackObj {
public:
// 状态枚举,含义
// TS_UNDEF,初始状态,未定义。
// TS_READY,就绪状态,准备抢锁。
// TS_RUN,正在运行(通常指正在尝试 CAS 抢锁)。
// TS_WAIT,在 WaitSet 中。对应 Java 层的 object.wait() 状态。
// TS_ENTER,在 EntryList 中。正在排队等待进入 synchronized 块。
// TS_CXQ,在 cxq 队列中。刚刚竞争失败,还没被挪到 EntryList。
enum TStates { TS_UNDEF, TS_READY, TS_RUN, TS_WAIT, TS_ENTER, TS_CXQ };
ObjectWaiter* volatile _next;
ObjectWaiter* volatile _prev;
JavaThread* _thread;
jlong _notifier_tid;
ParkEvent * _event;
volatile int _notified;
volatile TStates TState;
bool _active; // Contention monitoring is enabled
};
重量级锁阻塞的逻辑:
先调用 glibc 中的pthread.hpthread_mutex_lock 再调用system call futex
JVM对Synchronized的优化。简单来说解决三种场景:
- 只有一个线程进入临界区,偏向锁
- 多个线程交替进入临界区,轻量级锁
- 多线程同时进入临界区,重量级锁
Wait Sets and Notification
Every object, in addition to having an associated monitor, has an associated wait set. A wait set is a set of threads.
Wait sets are manipulated solely through the methods Object.wait, Object.notify, and Object.notifyAll.
Wait actions occur upon invocation of wait(), or the timed forms wait(long millisecs) and wait(long millisecs, int nanosecs).
Notification actions occur upon invocation of methods notify and notifyAll.
Let thread t be the thread executing either of these methods on object m, and let n be the number of lock actions by t on m that have not been matched by unlock actions. One of the following actions occurs:
- If n is zero, then an IllegalMonitorStateException is thrown. This is the case where thread t does not already possess the lock for target m.
- If n is greater than zero and this is a notify action, then if m’s wait set is not empty, a thread u that is a member of m’s current wait set is selected and removed from the wait set. There is no guarantee about which thread in the wait set is selected. This removal from the wait set enables u’s resumption in a wait action. Notice, however, that u’s lock actions upon resumption cannot succeed until some time after t fully unlocks the monitor for m.
- If n is greater than zero and this is a notifyAll action, then all threads are removed from m’s wait set, and thus resume. Notice, however, that only one of them at a time will lock the monitor required during the resumption of wait.
由于 wait() 与 notify/notifyAll() 是放在同步代码块中的,因此线程在执行它们时,肯定是进入了临界区中的,即该线程肯定是获得了锁的。
当线程执行wait()时,会把当前的锁释放,然后让出CPU,进入等待状态。
当执行notify/notifyAll方法时,会唤醒一个处于等待该 对象锁 的线程,然后继续往下执行,直到执行完退出对象锁锁住的区域(synchronized修饰的代码块)后再释放锁。
- If n is zero, then an IllegalMonitorStateException is thrown. This is the case where thread t does not already possess the lock for target m.
- If n is greater than zero and this is a
notifyaction, then if m’s wait set is not empty, a thread u that is a member of m’s current wait set is selected and removed from the wait set. There is no guarantee about which thread in the wait set is selected. This removal from the wait set enables u’s resumption in a wait action. Notice, however, that u’s lock actions upon resumption cannot succeed until some time after t fully unlocks the monitor for m. - If n is greater than zero and this is a
notifyAllaction, then all threads are removed from m’s wait set, and thus resume. Notice, however, that only one of them at a time will lock the monitor required during the resumption of wait.Interrupt
Interruption actions occur upon invocation of Thread.interrupt, as well as methods defined to invoke it in turn, such as ThreadGroup.interrupt.
interrupt这个东西的意思是什么呢?如果你是while循环,可以判断如果没有被中断,那么就正常工作,如果别人中断了这个线程,那么while循环的条件判断里,就会发现说,isInterrupted,被中断了
被中断了以后,你的while循环发现了,就会退出循环,这个线程就终止了
interrupt打断一个线程,其实是在修改那个线程里的一个interrupt的标志位,打断他以后,interrupt标志位就会变成true,所以在线程内部,可以根据这个标志位,isInterrupted这个标志位来判断,是否要继续运行
并不是说,直接interrupt一下某个线程,直接就不让他运行了
还有一个更加常见的用法,就是说什么呢?打断一个线程的休眠或者是wait,等一些block的状态
Interactions of Waits, Notification, and Interruption
notifications cannot be lost due to interrupts
Sleep and Yield
Thread.sleep, The thread does not lose ownership of any monitors, and resumption of execution will depend on scheduling and the availability of processors on which to execute the thread.
In particular, the compiler does not have to flush writes cached in registers out to shared memory before a call to Thread.sleep or Thread.yield, nor does the compiler have to reload values cached in registers after a call to Thread.sleep or Thread.yield.
1
2
3
void sleepAWhile() throws Exception{
Thread.sleep(2000L);
}
void sleepAWhile() throws java.lang.Exception;
descriptor: ()V
flags:
Code:
stack=2, locals=1, args_size=1
0: ldc2_w #2 // long 2000l
3: invokestatic #4 // Method java/lang/Thread.sleep:(J)V
6: return
LineNumberTable:
line 4: 0
line 5: 6
Exceptions:
throws java.lang.Exception
JUC
java.util.concurrent包
解决并发问题的方法有哪些
- 有锁
- synchronized
- ReentrantLock
- 无锁
- 局部变量
- 不可变对象
- ThreadLocal(线程封闭技术)
- cas原子类
CAS
乐观锁原理
Compare-and-swap
AtomicInteger源码 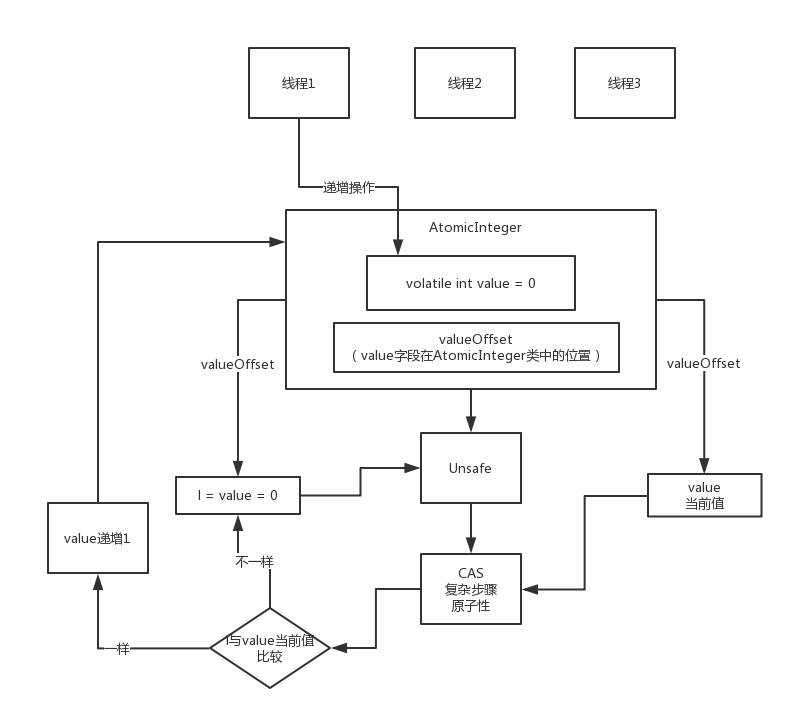
CPU保证操作的原子性
存在的问题:
- ABA问题 如果某个值一开始是A,后来变成了B,然后又变成了A,你本来期望的是值如果是第一个A才会设置新值,结果第二个A一比较也ok,也设置了新值,跟期望是不符合的。所以atomic包里有
AtomicStampedReference类或者是AtomicMarkableReference,就是会比较两个值的引用是否一致,如果一致,才会设置新值 - 无限循环问题 JDK 1.8引入的
LongAdder来解决,是一个重点,分段CAS思路 - 多变量原子问题 一般的
AtomicInteger,只能保证一个变量的原子性,但是如果多个变量呢?你可以用AtomicReference,这个是封装自定义对象的,多个变量可以放一个自定义对象里,然后他会检查这个对象的引用是不是一个
AQS & Locks
AbstractQueuedSynchronizer,基于CAS的无锁化逻辑
ReentrantLock
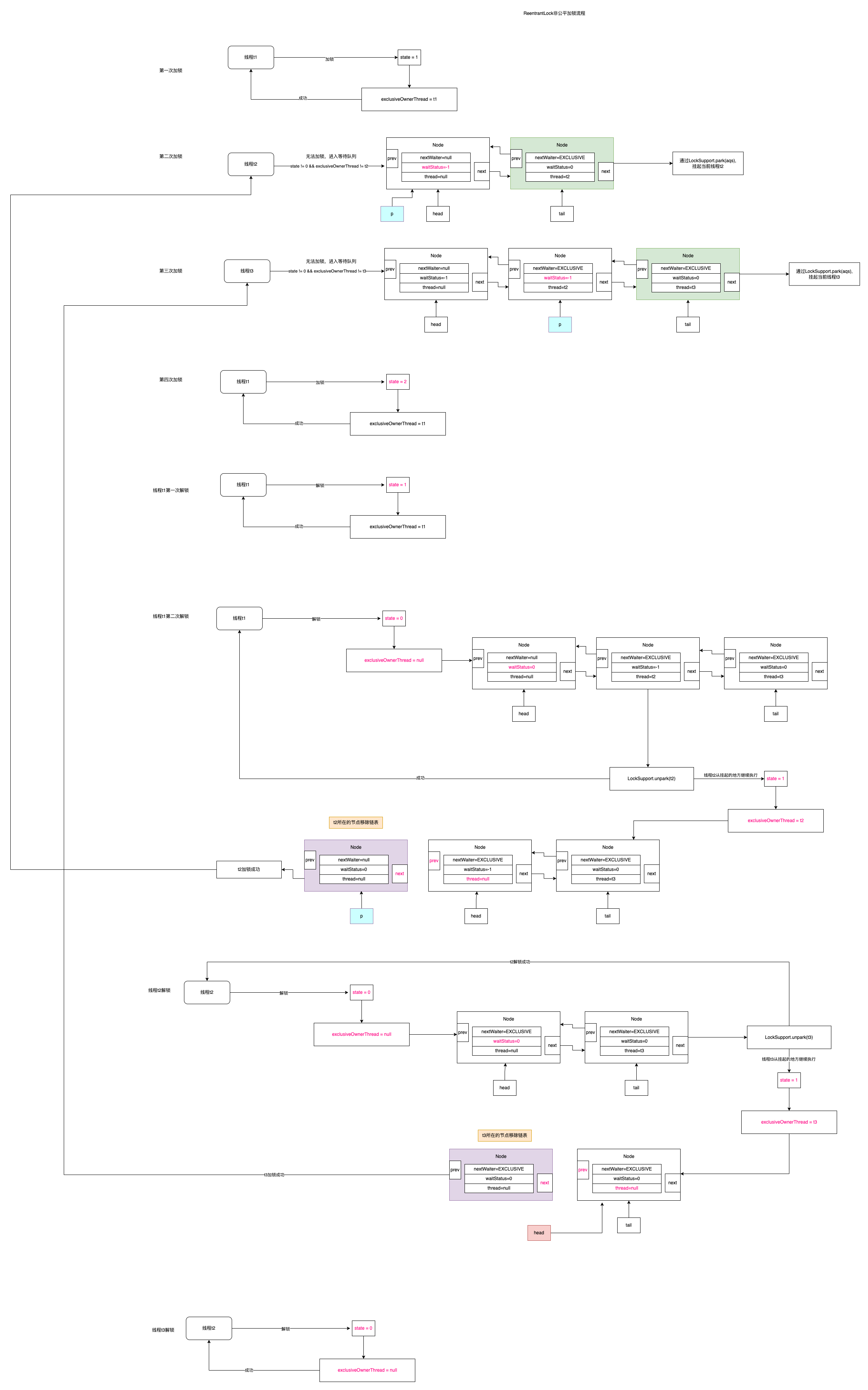
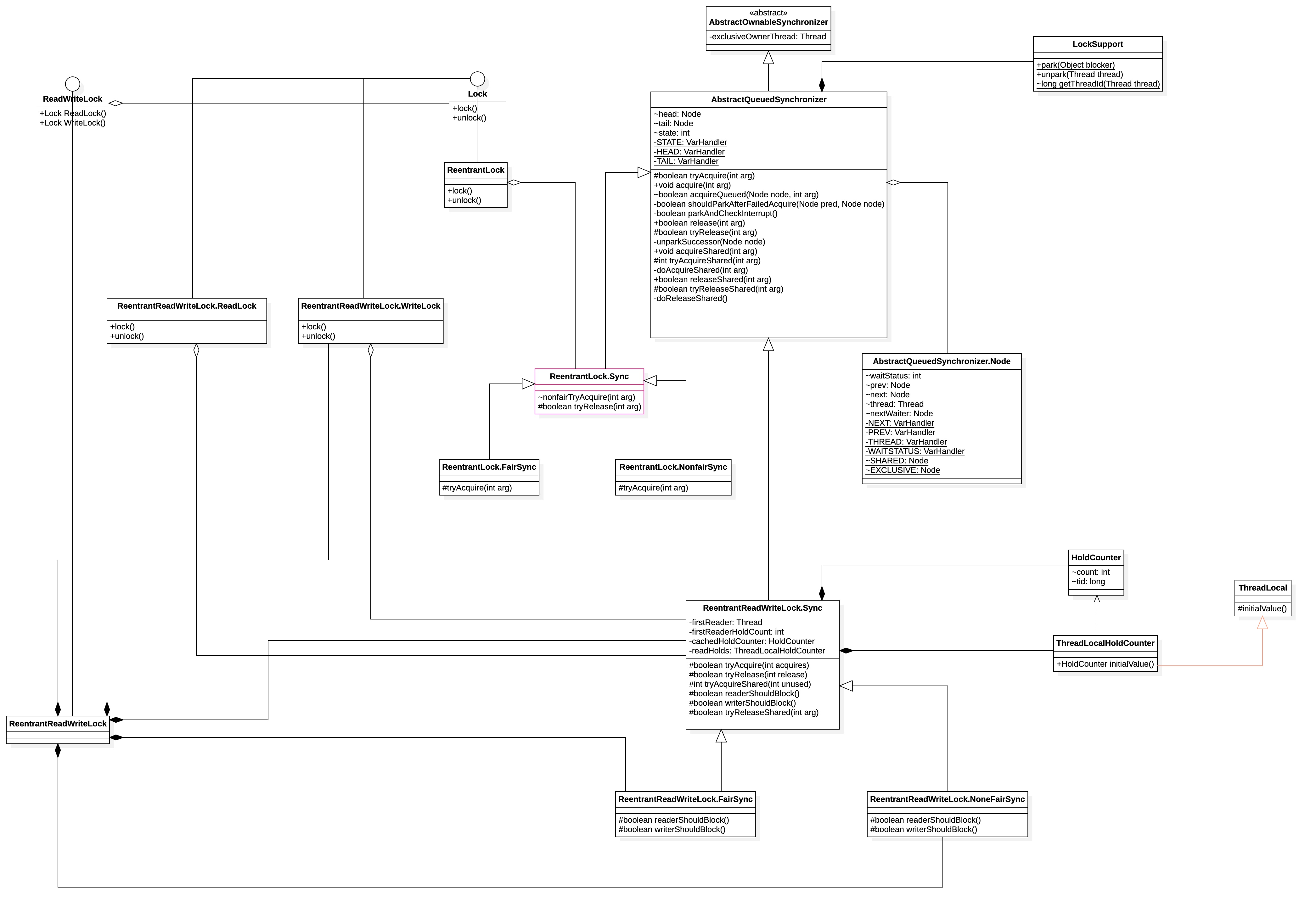
公平锁和非公平锁: 非公平锁就是: 新进来的锁可能会不进入等待队列而直接拿到 公平锁: 新来的排队就完了
优点: 基于CAS的的无锁化处理的 缺点: JDK1.6之后 synchrynized 底层优化的比较好,所以真正在开发过程中, 如果需要用synchronized话,优先使用。
ReentrantReadWriteLock
写锁是 exclusive 独占的排他锁 读锁是 shared 共享锁 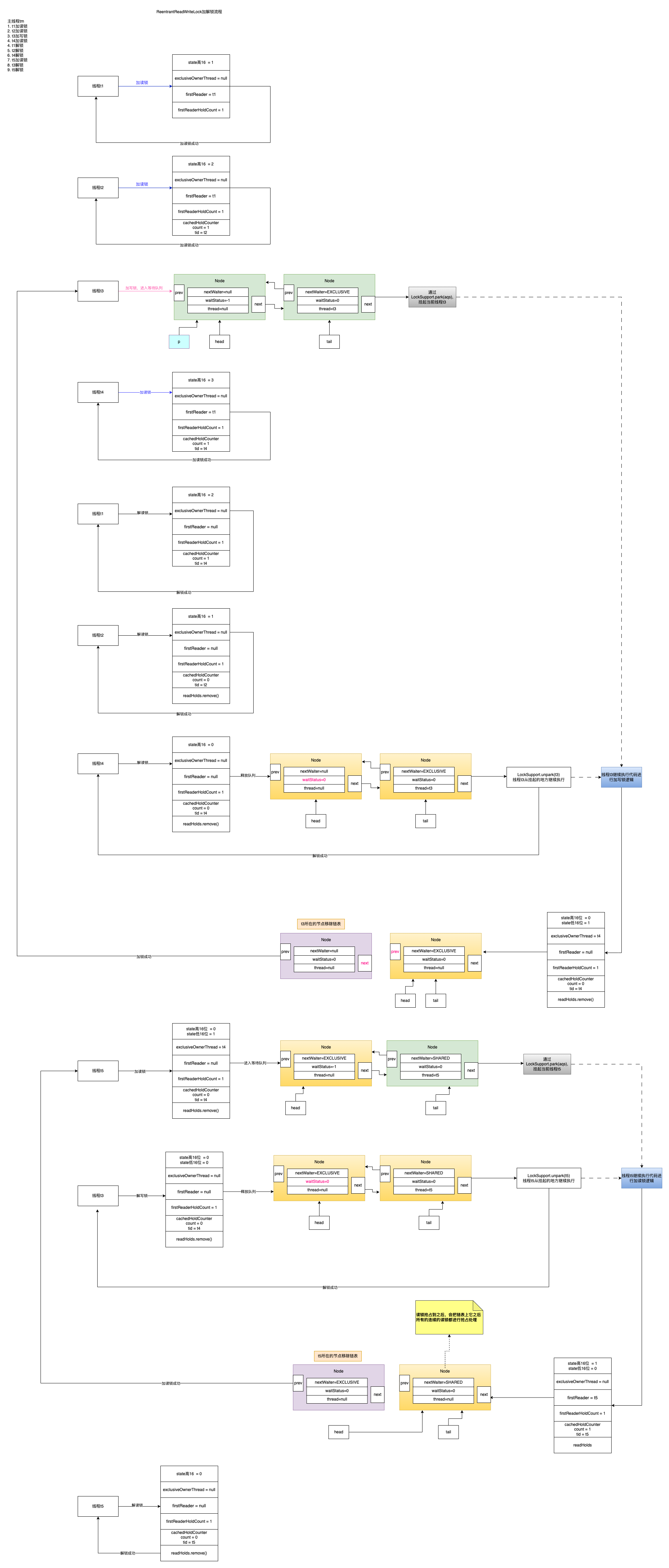
也是区分公平和非公平锁的,默认是非公平锁: 非公平锁就是: 新进来的读锁或者写锁可能会不进入等待队列而直接拿到,这样可能会导致读锁一直可以拿到,导致写锁饥饿 公平锁: 读-读锁不用排队直接获取锁 读-写锁直接进入等待队列 写-写锁直接进入等待队列 写-读锁直接进入等待队列
优点:就是读锁之间不是互斥的不像synchronized所有的都互斥,这样可以提高并发, 缺点: ReentrantReadWriteLock实现了读写分离,想要获取读锁就必须确保当前没有其他任何读写锁了,但是一旦读操作比较多的时候,想要获取写锁就变得比较困难了,因为当前有可能会一直存在读锁。而无法获得写锁。 使用场景: 读多写少的场景
Condition
实现了wait(),notify(),notifyAll()机制 下面是代码示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
ReentrantReadWriteLock readWriteLock = new ReentrantReadWriteLock();
ReentrantReadWriteLock.WriteLock writeLock = readWriteLock.writeLock();
Condition condition = writeLock.newCondition();
Thread t1 = new Thread(() -> {
writeLock.lock();
System.out.println("线程t1主动让出锁");
try {
condition.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("线程t1主动让出锁后恢复");
writeLock.unlock();
});
Thread t2 = new Thread(() -> {
writeLock.lock();
System.out.println("线程t2开始执行");
try {
Thread.sleep(2000L);
} catch (InterruptedException e) {
e.printStackTrace();
}
condition.signal();
System.out.println("线程t2通知condition" +
"");
writeLock.unlock();
System.out.println("线程t2结束执行");
});
t1.start();
try {
Thread.sleep(500L);
} catch (InterruptedException e) {
e.printStackTrace();
}
t2.start();
t1.join();
t2.join();
输出结果
1
2
3
4
5
线程t1主动让出锁
线程t2开始执行
线程t2通知condition
线程t2结束执行
线程t1主动让出锁后恢复
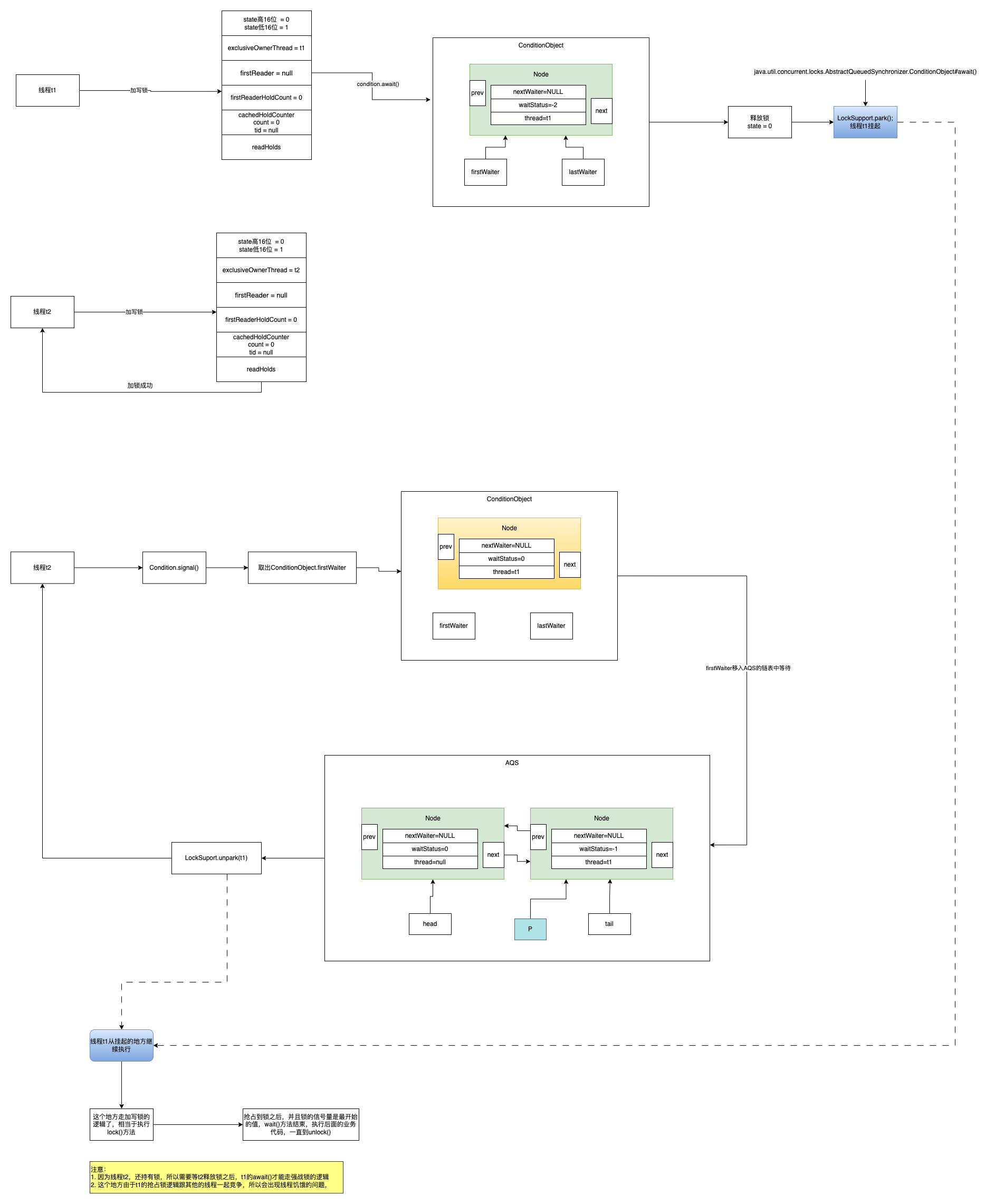
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
class MyBlockingQueue {
private final String[] items = new String[5]; // 队列容量为 5
private int putIndex, takeIndex, count;
private final Lock lock = new ReentrantLock();
// 定义两个 Condition:精准控制“满”和“空”
private final Condition notFull = lock.newCondition();
private final Condition notEmpty = lock.newCondition();
// 生产者方法
public void put(String val) throws InterruptedException {
lock.lock(); // 获取锁
try {
while (count == items.length) {
System.out.println("队列满了,生产者等待...");
notFull.await(); // 1. 在 notFull 频道等待
}
items[putIndex] = val;
if (++putIndex == items.length) putIndex = 0;
count++;
System.out.println("生产了: " + val);
notEmpty.signal(); // 2. 定向唤醒在 notEmpty 频道等的消费者
} finally {
lock.unlock(); // 释放锁
}
}
// 消费者方法
public String take() throws InterruptedException {
lock.lock();
try {
while (count == 0) {
System.out.println("队列空了,消费者等待...");
notEmpty.await(); // 3. 在 notEmpty 频道等待
}
String val = items[takeIndex];
if (++takeIndex == items.length) takeIndex = 0;
count--;
System.out.println("消费了: " + val);
notFull.signal(); // 4. 定向唤醒在 notFull 频道等的生产者
return val;
} finally {
lock.unlock();
}
}
}
StampedLock
StampedLock 并没有实现Lock接口
为了解决ReentrantReadWriteLock写线程饥饿的问题,JDK1.8发布的新的类来处理此问题StampedLock, 声明了三种操作模式
- Writing
- Reading
- Optimistic Reading (乐观读)
个人认为也挺重要的但是没有时间学了。。 https://cloud.tencent.com/developer/article/1829985
CountDownLatch
基于AQS实现的栅栏的效果,等待多个线程完成任务 类图 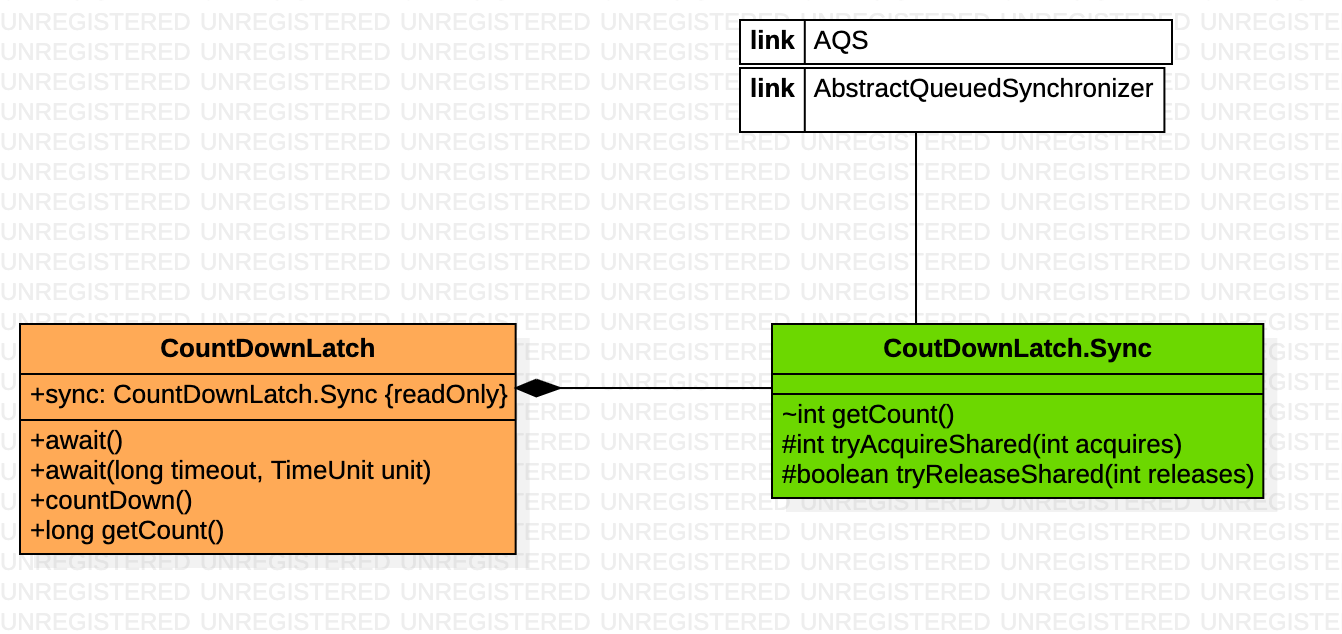
运行逻辑图示 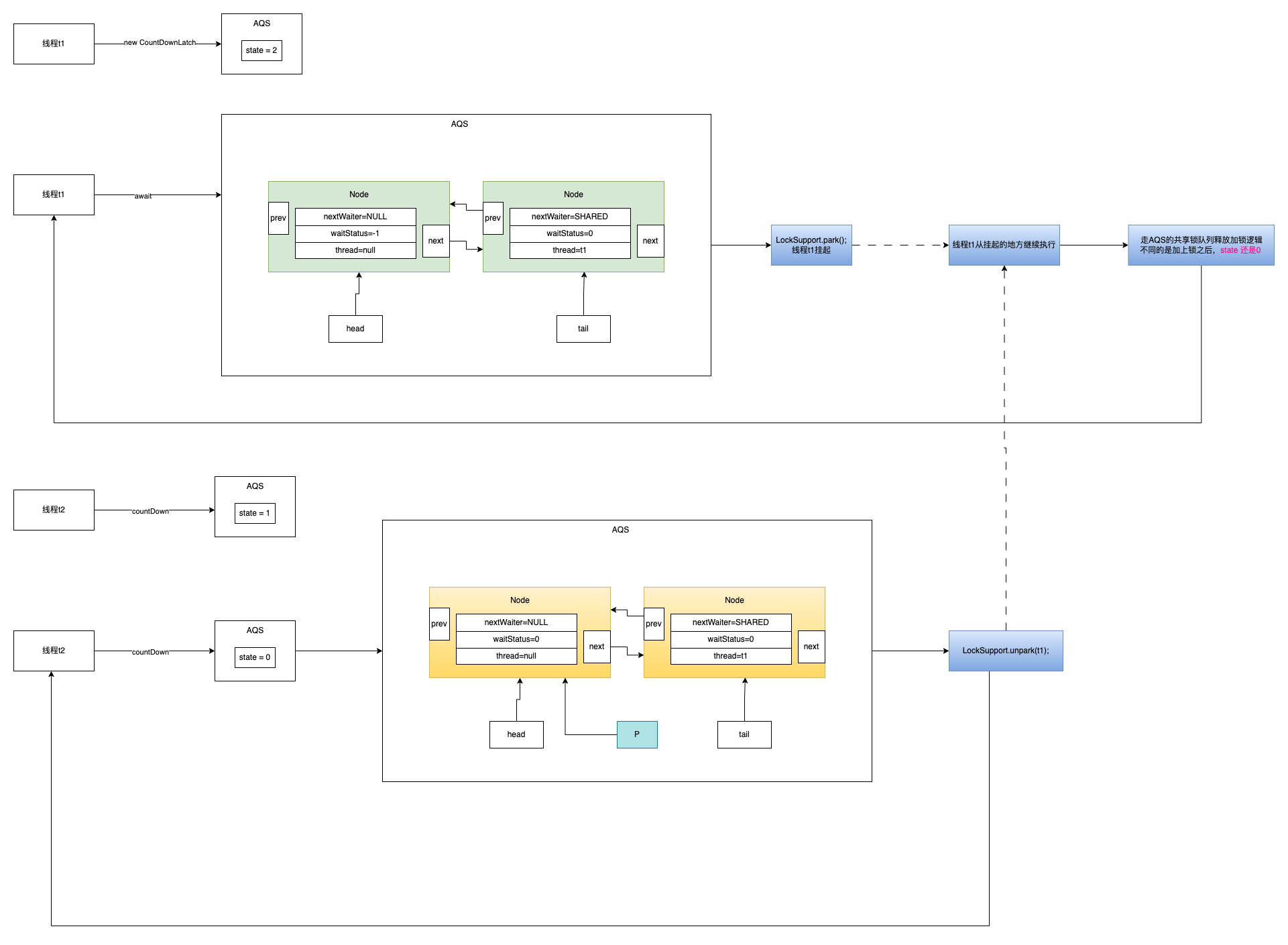
CyclicBarrier
将工作任务给多线程分而治之的并发组件,子任务拆分后,主线程不阻塞,但是用的很少 代码示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
CyclicBarrier cyclicBarrier = new CyclicBarrier(2,() -> {
System.out.println("子任务全部执行完毕");
});
Thread t1 = new Thread(() -> {
try {
Thread.sleep(100);
System.out.println("线程t1完成子任务");
cyclicBarrier.await();
} catch (Exception e) {
e.printStackTrace();
}
});
Thread t2 = new Thread(() -> {
try {
Thread.sleep(100);
System.out.println("线程t2完成子任务");
cyclicBarrier.await();
} catch (Exception e) {
e.printStackTrace();
}
});
t1.start();
t2.start();
System.out.println("主线程结束");
输出结果
1
2
3
4
主线程结束
线程t2完成子任务
线程t1完成子任务
子任务全部执行完毕
Semaphore
指定数量的线程完成任务的并发组件,用的很少 代码示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
Semaphore semaphore = new Semaphore(1,true);
Thread t1 = new Thread(() -> {
try {
semaphore.acquire();
Thread.sleep(500);
System.out.println("线程t1完成子任务");
semaphore.release();
} catch (Exception e) {
e.printStackTrace();
}
});
Thread t2 = new Thread(() -> {
try {
semaphore.acquire();
Thread.sleep(1000);
System.out.println("线程t2完成子任务");
semaphore.release();
} catch (Exception e) {
e.printStackTrace();
}
});
t1.start();t2.start();
System.out.println("主线程结束");
输出结果
1
2
3
主线程结束
线程t1完成子任务
线程t2完成子任务
ThreadLocal
线程封闭技术
并发编程里非常常用的一个东西,ThreadLocal,线程本地副本

内存泄漏问题? 线程在退出之前,JVM会自动调用线程的exit()方法,来做一些清理工作。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
private void exit() {
if (threadLocals != null && TerminatingThreadLocal.REGISTRY.isPresent()) {
TerminatingThreadLocal.threadTerminated();
}
if (group != null) {
group.threadTerminated(this);
group = null;
}
/* Aggressively null out all reference fields: see bug 4006245 */
target = null;
/* Speed the release of some of these resources */
threadLocals = null; // 在这里会把threadLocals的引用设置为null 这样的话就会防止ThreadLocal的数据造成内存泄漏
inheritableThreadLocals = null;
inheritedAccessControlContext = null;
blocker = null;
uncaughtExceptionHandler = null;
}
但是其实有个比较极端的场景,如果使用的是线程池的话,你的任务里有各种不同的ThreadLocal, 也可能会导致内存泄漏,但是正常情况下一个线程池,只针对一个类型的任务。一般人不会这么写代码。
为什么Entry要继承WeakReference?
显而易见的就是为了加快GC,但是这里面有一些陷阱,因为只有Entry的key是弱引用,其他的相关的都是强引用。
 陷阱:
陷阱:
- When we look at ThreadLocalMap above, we know that key is a weak reference, and key will be recycled when gc, but value and ThreadLocalMap references will not be recycled. If there are a lot of Threads in this case and they have not been executed, there may be a memory leak.
- When using thread pools, if you use ThreadLocal to call the set method and then do not call remove, because the threads in the thread pool are multiplexed, if the same thread calls the get method again, you may get a value that is not the one set in at that time, resulting in a program data exception or something like that. Try to remove the value after using it.
- Whether it is normal to use or thread pool use ThreadLocal must be removed after use, otherwise, there will be memory leaks or data errors
Exchanger
这个用的特别少,用来实现线程间的数据交换,基于ThreadLocal做的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
Exchanger<String> exchanger = new Exchanger<>();
new Thread(()-> {
try {
String data = exchanger.exchange("线程1的数据");
System.out.println("线程1获取到交换的数据:" + data);
} catch (Exception e) {
e.printStackTrace();
}
}).start();
new Thread(()-> {
try {
String data = exchanger.exchange("线程2的数据");
System.out.println("线程2获取到交换的数据:" + data);
} catch (Exception e) {
e.printStackTrace();
}
}).start();
输出结果
1
2
线程2获取到交换的数据:线程1的数据
线程1获取到交换的数据:线程2的数据
锁优化原则
- 标志位修改等可见性场景优先使用volatile
- 数值递增场景优先使用Atomic原子类
- 数据允许多副本的情况下优化使用ThreadLocal
- 读多写少的场景如果需要加锁的话优化读写锁
- 尽可能减少线程对锁的占用时间
- 尽可能减少线程的加锁粒度
- 尽可能对不同功能分离锁的使用
- 尽量减少高并发场景中线程对锁的争用
- 避免在循环中频繁的加锁和释放锁
- 可采用多级缓存的方式降低对锁的竞争
锁故障排查分析
死锁
一段可以发生死锁的代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
int loop = 1000;
Thread t1 = new Thread(() -> {
for (int i = 0; i < loop; i++) {
synchronized (a) {
try {
Thread.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (b) {
try {
Thread.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
});
Thread t2 = new Thread(() -> {
for (int i = 0; i < loop; i++) {
synchronized (b) {
try {
Thread.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (a) {
try {
Thread.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
});
t1.start();
t2.start();
t1.join();
t2.join();
使用jstack命令能看出程序是否发生了死锁
1
jstack PID
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
"Thread-0" #13 prio=5 os_prio=31 cpu=11.96ms elapsed=314.11s tid=0x00007f92dcd70000 nid=0x8603 waiting for monitor entry [0x000000030a688000]
java.lang.Thread.State: BLOCKED (on object monitor)
at com.peng.alltest.javase.concurrent.DeadLockTest.lambda$moni$0(DeadLockTest.java:27)
- waiting to lock <0x0000000787ee9db8> (a java.lang.Object)
- locked <0x0000000787ee9da8> (a java.lang.Object)
at com.peng.alltest.javase.concurrent.DeadLockTest$$Lambda$14/0x0000000800066c40.run(Unknown Source)
at java.lang.Thread.run(java.base@11.0.12/Thread.java:834)
"Thread-1" #14 prio=5 os_prio=31 cpu=10.46ms elapsed=314.11s tid=0x00007f92dc812000 nid=0xa803 waiting for monitor entry [0x000000030a78b000]
java.lang.Thread.State: BLOCKED (on object monitor)
at com.peng.alltest.javase.concurrent.DeadLockTest.lambda$moni$1(DeadLockTest.java:47)
- waiting to lock <0x0000000787ee9da8> (a java.lang.Object)
- locked <0x0000000787ee9db8> (a java.lang.Object)
at com.peng.alltest.javase.concurrent.DeadLockTest$$Lambda$15/0x0000000800066440.run(Unknown Source)
at java.lang.Thread.run(java.base@11.0.12/Thread.java:834)
Found one Java-level deadlock:
=============================
"Thread-0":
waiting to lock monitor 0x00007f92b002a000 (object 0x0000000787ee9db8, a java.lang.Object),
which is held by "Thread-1"
"Thread-1":
waiting to lock monitor 0x00007f92b000ff00 (object 0x0000000787ee9da8, a java.lang.Object),
which is held by "Thread-0"
Java stack information for the threads listed above:
===================================================
"Thread-0":
at com.peng.alltest.javase.concurrent.DeadLockTest.lambda$moni$0(DeadLockTest.java:27)
- waiting to lock <0x0000000787ee9db8> (a java.lang.Object)
- locked <0x0000000787ee9da8> (a java.lang.Object)
at com.peng.alltest.javase.concurrent.DeadLockTest$$Lambda$14/0x0000000800066c40.run(Unknown Source)
at java.lang.Thread.run(java.base@11.0.12/Thread.java:834)
"Thread-1":
at com.peng.alltest.javase.concurrent.DeadLockTest.lambda$moni$1(DeadLockTest.java:47)
- waiting to lock <0x0000000787ee9da8> (a java.lang.Object)
- locked <0x0000000787ee9db8> (a java.lang.Object)
at com.peng.alltest.javase.concurrent.DeadLockTest$$Lambda$15/0x0000000800066440.run(Unknown Source)
at java.lang.Thread.run(java.base@11.0.12/Thread.java:834)
Found 1 deadlock.
解决这种死锁的方式就是,写代码的时候按照相同的加锁顺序来加锁
锁死问题
问题出现的原因就是调用了wait()方法之后,没有人调用notify()
1
2
3
4
5
6
7
8
9
10
11
12
synchronized (a) {
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
try {
a.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
排查方式使用jstack
线程饥饿
线程饥饿是指线程一直无法获得所需要的资源导致任务一直无法执行的一种活性故障
活锁
活锁指的是任务或者执行者没有被阻塞,由于某些条件没有满足,导致一直重复尝试,失败,尝试,失败
发生指令重排的地方
- javac编译成class文件的时候
- jit编译成机器码的时候
- CPU实际执行的时候也可能会发生指令重排
总体上在遵循happens-before原则的前提下,且不影响单线程的执行结果,你爱怎么排怎么排。
并发集合
ConcurrentHashMap
有几个保证并发线程安全的点
- get操作不加锁
- 主要是访问table中的元素使用unsafe中的原子操作
- put操作的时候
- table初始化的时候CAS + 自旋循环来保证并发安全
- 访问、赋值table中的元素使用unsafe中的原子操作
- hash冲突的时候通过synchronized锁来进行分段加锁
- 包括当hash冲突时链表长度 > 8 && table的长度 >= 64的时候才会转成红黑树,如果是table的长度小于64的时候会直接自动扩容 - 分段锁的思想
- 都是对数组的一个元素加锁而已
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh; K fk; V fv;
if (tab == null || (n = tab.length) == 0)
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value)))
break; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else if (onlyIfAbsent // check first node without acquiring lock
&& fh == hash
&& ((fk = f.key) == key || (fk != null && key.equals(fk)))
&& (fv = f.val) != null)
return fv;
else {
V oldVal = null;
// HashMap并发环境下最严重的问题就是Hash冲突的问题
synchronized (f) {
if (tabAt(tab, i) == f) { // 这个地方算是个double check
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
// hash冲突的情况下把node放到链表的末尾
pred.next = new Node<K,V>(hash, key, value);
break;
}
}
}
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
else if (f instanceof ReservationNode)
throw new IllegalStateException("Recursive update");
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}
// 初次put操作,初始化table数组
private final Node<K,V>[] initTable() {
Node<K,V>[] tab; int sc;
while ((tab = table) == null || tab.length == 0) {
if ((sc = sizeCtl) < 0)
Thread.yield(); // lost initialization race; just spin
// 下面的判断通过CAS的方式来保证并发安全性的
else if (U.compareAndSetInt(this, SIZECTL, sc, -1)) {
try {
if ((tab = table) == null || tab.length == 0) {
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = tab = nt;
// table初始化之后,存储的是再次resizing的阈值
// n - n/4 = 3/4n = 0.75n 这个地方已经把自动扩容的系数给写死了
sc = n - (n >>> 2);
}
} finally {
sizeCtl = sc;
}
break;
}
}
return tab;
}
- size操作 put操作的时候维护数量跟
LongAdder差不多,也是有BaseCount + CellCount数组CopyOnWriteArrayList
这个特别简单
add、remove操作 都会synchronized一个全局的对象锁,每次操作都会把数据copy到一个新的数组中去 值的一提的是现在看到的是jdk11的源码,jdk8的时候使用ReentrantLock来替代synchronized,可见随着JVM的底层对锁的优化,synchronized的性能已经很好了。get、size等查询操作就没有锁直接访问,iterator()迭代的时候也是读的是一份快照,不用加锁
这种的适合读多写少的场景
ConcurrentLinkedQueue
CAS + 自旋保证线程安全的
LinkedBlockingQueue
takeLock + putLock 分离锁 ReentrantLock使用的是
ArrayBlockingQueue
全局的 ReentrantLock 控制所有的操作
对比三种queue https://cloud.tencent.com/developer/beta/article/1340017
SynchronousQueue
没有线程在等待获取任务的时候,入队直接是返回false的,不让你入队成功。必须要有人在等待获取任务,才能入队成功 提交的任务几乎是不会排队的,永远能最快速度的得到执行,入队的时候先看看有没有人空闲在poll,如果有立马执行.
线程池
 what
what
why
how
ThreadPoolExecutor
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
/**
* @param corePoolSize the number of threads to keep in the pool, even
* if they are idle
* @param maximumPoolSize the maximum number of threads to allow in the
* pool
* @param keepAliveTime when the number of threads is greater than
* the core, this is the maximum time that excess idle threads
* will wait for new tasks before terminating.
* @param unit the time unit for the keepAliveTime argument
* @param workQueue the queue to use for holding tasks before they are
* executed. This queue will hold only the {@code Runnable}
* tasks submitted by the {@code execute} method.
* @param threadFactory the factory to use when the executor
* creates a new thread
* @param handler the handler to use when execution is blocked
* because the thread bounds and queue capacities are reached
*/
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
}
注意: 如果keepAliveTime = 0,则超过corePoolSize部分的线程会在拿不到任务的时候直接失效
线程池的状态:
- RUNNING: Accept new tasks and process queued tasks
- SHUTDOWN: Don’t accept new tasks, but process queued tasks
- STOP: Don’t accept new tasks, don’t process queued tasks, and interrupt in-progress tasks
- TIDYING: All tasks have terminated, workerCount is zero, the thread transitioning to state TIDYING will run the terminated() hook method
- TERMINATED: terminated() has completed

参数配置原则
首先确定服务几个相关参数:
- tasks_most 单台机器大部分时间段的qps,可以采用28原则来取值
- tasks_max 单台机器峰值的qps
- tasktime_avg 任务的平均处理时间 单位秒
- responsetime_max 系统允许任务最大的响应时间 单位秒
- cpu_core 机器cpu的核心数量 假设: tasks_most = 1000 tasks_max = 3000 tasktime_avg = 0.2 responsetime_max = 1
corePoolSize = tasks_most/(1/tasktime_avg) = tasks_most * tasktime_avg = 200 还得根据本身机器的配置来看,如果得到的结果
queueCapacity = (corePoolSize/tasktime) * responsetime
每秒200个任务需要20个线程,那么当每秒达到1000个任务时 maxPoolSize = (1000-queueCapacity) * (20/200)
ScheduledThreadPoolExecutor
本质上还是通过DelayedWorkQueue来实现的
Executors
快速生成ThreadPoolExecutor的工具类
1
2
3
4
5
Executors.newFixedThreadPool(1);
Executors.newCachedThreadPool();
Executors.newSingleThreadScheduledExecutor();
Executors.newWorkStealingPool();
Executors.newScheduledThreadPool(1);
ForkJoinPool
Stream并行计算
1
2
3
4
5
6
7
8
9
10
11
12
public class StreamParallelDemo {
public static void main(String[] args) {
Stream.of(1, 2, 3, 4, 5, 6, 7, 8, 9)
.parallel()
.reduce((a, b) -> {
System.out.println(String.format("%s: %d + %d = %d",
Thread.currentThread().getName(), a, b, a + b));
return a + b;
})
.ifPresent(System.out::println);
}
}
底层依赖的就是JDK的ForkJoin框架